


与其他高级编程语言相比,C 语言可以更高效地对计算机硬件进行操作,而计算机硬件的操作指令,在很大程度上依赖于地址。
指针提供了对地址操作的一种方法,因此,使用指针可使得 C 语言能够更高效地实现对计算机底层硬件的操作。另外,通过指针可以更便捷地操作数组。在一定意义上可以说,指针是 C 语言的精髓。
内存与地址
在计算机中,数据是存放在内存单元中的,一般把内存中的一个字节称为一个内存单元。为了更方便地访问这些内存单元,可预先给内存中的所有内存单元进行地址编号,根据地址编号,可准确找到其对应的内存单元。由于每一个地址编号均对应一个内存单元,因此可以形象地说一个地址编号就指向一个内存单元。C 语言中把地址形象地称作指针。
C语言中的每个变量均对应内存中的一块内存空间,而内存中每个内存单元均是有地址编号的。在 C 语言中,可以使用运算符 & 求某个变量的地址。
例如,在如下代码中,定义了字符型变量 c 和整型变量 a,并分别赋初值 ‘A’ 和 100。
- #include<stdio.h>
- intmain(void)
- {
- char c=‘A’;
- int a=100;
- printf(“a=%d\n“,a);//输出变量a的值
- printf(“&a=%x\n“,&a);//输出变量a的地址
- printf(“c=%c\n“,c);
- printf(“&c=%x\n“,&c);
- return0;
- }
程序某次的运行结果为:
a=100
&a=12ff40
c=A
&c=12ff44
分析:
在 C 语言中,字符型变量占一个字节的内存空间,而整型变量所占字节数与系统有关。例如,在 32 位系统中,VC++6.0 开发环境中,int 型占 4 个字节。假设程序在某次运行时,变量 a 和 c 在内存中的分配情况如图 1 所示:内存单元(每个字节)的地址编号分别为十六进制表示的 …12ff40、12ff41、12ff42、12ff43、12ff44…,每个地址编号均为对应字节单元的起始地址。

由图 1 可知,变量 a 对应于从地址 12ff40 开始的 4 个字节(12ff40、12ff41、12ff42、12ff43)的内存空间,存储的是整数 100 的 32 位二进制形式(为直观表示,本例并没有转换成二进制形式)。字符型变量 c,对应地址为 12ff44,该地址内存储的是字母对应 ASCII 值的 8 位二进制形式。
语句 printf(“a=%d\n”,a); 输出:a=100。
语句 printf(“&a=%x\n”,&a); 是按十六进制形式输出变量 a 的地址(a 在内存中的起始地址值)为 &a=12ff40。
在上例中,变量 a 和 c 的起始地址 12ff40 和 12ff44 均为指针,分别指向变量 a 和变量 c。
区分变量的地址值和变量的值。如上例中,变量 a 的地址值(指针值)为12ff40,而变量 a 的值为 100。
指针变量的定义
可以保存地址值(指针)的变量称为指针变量,因为指针变量中保存的是地址值,故可以把指针变量形象地比喻成地址箱。
指针变量的定义形式如下。
类型 * 变量名;
例如:
- int*pa;
定义了一个整型指针变量 pa,该指针变量只能指向基类型为 int 的整型变量,即只能保存整型变量的地址。
说明:
1) *号标识该变量为指针类型,当定义多个指针变量时,在每个指针变量名前面均需要加一个 *,不能省略,否则为非指针变量。例如:
- int*pa,*pb;
表示定义了两个指针变量 pa、pb。而:
int *pa,pb;
则仅有 pa 是指针变量,而 pb 是整型变量。
- int*pi,a,b;//等价于inta,b,*pi;
表示定义了一个整型指针变量 pi 和两个整型变量 a 和 b。
2) 在使用已定义好的指针变量时,在变量名前面不能加 *。例如:
- int*p,a;
- *p=&a;//错误,指针变量是p而不是*p
而如下语句是正确的。
- int a,*p=&a;//正确
该语句貌似把 &a 赋给了 *p,而实际上 p 前的 * 仅是定义指针变量 p 的标识,仍然是把 &a 赋给了 p,故是正确的赋值语句。
3) 类型为该指针变量所指向的基类型,可以为 int、char、float 等基本数据类型,也可以为自定义数据类型。
该指针变量中只能保存该基类型变量的地址。
假设有如下变量定义语句:
- int a,b,*pa,*pb;
- char*pc,c;
则:
- pa=&a;//正确。pa基类型为int,a为int型变量,类型一致
- pb=&c;//错误。pb基类型为int,c为char型变量,类型不一致
- pc=&c;//正确。pc基类型为char,c为char型变量,类型一致
- *pa=&a;//错误。指针变量是pa而非*pa
4) 变量名是一合法标识符,为与普通变量相区分,一般指针变量名以字母 p(pointer)开头,如 pa、pb 等。
5) 由于是变量,故指针变量的值可以改变,也即可以改变指针变量的指向。
- char c1,*pc,c2;//定义了字符变量c1、c2和字符指针变量pc
则如下对指针变量的赋值语句均是正确的。
- pc=&c1;//pc指向c1
- pc=&c2;//pc不再指向c1,而指向c2
6) 同类型的指针变量可以相互赋值。
- int a,*p1,*p2,b;//定义了两个整型变量a,b;两个整型指针变量为p1,p2
- float*pf;
以下赋值语句均是正确的。
- p1=&a;//地址箱p1中保存a的地址,即p1指向a
- p2=p1;//p2也指向a,即p1和p2均指向a
上述最后一条赋值语句相当于把地址箱 p1 中的值赋给地址箱 p2,即 p2 中也保存 a 的地址,即和 p1 —样,p2 也指向变量 a。
以下赋值语句均是错误的。
- pf=p1; //错误。p1,pf虽然都是指针变量,但类型不同,不能赋值
- pf=&b;//错误。指针变量pf的基类型为float,b类型为int,不相同
由于指针变量是专门保存地址值(指针)的变量,故本节把指针变量形象地看成“地址箱”。
设有如下定义语句:
- int a=3,*pa=&a;//pa保存变量a的地址,即指向a
- char c=‘d’,*pc=&c;//pc保存变量c的地址,即指向c
把整型变量 a 的地址赋给地址箱 pa,即 pa 指向变量 a,同理 pc 指向变量 c,如图 2 所示。
指针变量的引用
访问内存空间,一般分为直接访问和间接访问。
如果知道内存空间的名字,可通过名字访问该空间,称为直接访问。由于变量即代表有名字的内存单元,故通。过变量名操作变量,也就是通过名字直接访问该变量对应的内存单元。
如果知道内存空间的地址,也可以通过该地址间接访问该空间。对内存空间的访问操作一般指的是存、取操作,即向内存空间中存入数据和从内存空间中读取数据。
在 C 语言中,可以使用间接访问符(取内容访问符)*来访问指针所指向的空间。
例如:
- int*p,a=3;//p中保存变量a对应内存单元的地址
- p=&a;
在该地址 p 前面加上间接访问符 *,即代表该地址对应的内存单元。而变量 a 也对应该内存单元,故 *p 就相当于 a。
- printf(“a=%d\n“,a);//通过名字,直接访问变量a空间(读取)
- printf(“a=%d\n“,*p);//通过地址,间接访问变量a空间(读取)
- *p=6;//等价于a=6;间接访问a对应空间(存)
“野”指针
本节中,把没有合法指向的指针称为“野”指针。因为“野”指针随机指向一块空间,该空间中存储的可能是其他程序的数据甚至是系统数据,故不能对“野”指针所指向的空间进行存取操作,否则轻者会引起程序崩溃,严重的可能导致整个系统崩溃。
例如:
- int*pi,a;//pi未初始化,无合法指向,为“野”指针
- *pi=3;//运行时错误!不能对”野”指针指向的空间做存入操作。该语句试图把 3 存入“野”指针pi所指的随机空间中,会产生运行时错误。
- a=*pi;//运行时错误!不能对”野”指针指向的空间取操作。该语句试图从“野”指针pi所指的空间中取出数据,然后赋给变量a同样会产生运行时错误。
正确的使用方法:
- pi=&a;//让pi有合法的指向,pi指向a变量对应的空间
- *pi=3;//把3间接存入pi所指向的变量a对应的空间
指针与数组
数组是一系列相同类型变量的集合,不管是一维数组还是多维数组其存储结构都是顺序存储形式,即数组中的元素是按一定顺序依次存放在内存中的一块连续的内存空间中(地址连续)。
指针变量类似于一个地址箱,让其初始化为某个数组元素的地址,以该地址值为基准,通过向前或向后改变地址箱中的地址值,即可让该指针变量指向不同的数组元素,从而达到通过指针变量便可以方便地访问数组中各元素的目的。
一维教组和指针
在 C 语言中,指针变量加 1 表示跳过该指针变量对应的基类型所占字节数大小的空间。指向数组元素的指针,其基类型为数组元素类型,指针加 1 表示跳过一个数组元素空间,指向下一个数组元素。
例如:
- int*p,a[10];
- p=a;//相当于 p=&a[0];
说明:数组名 a 相当于数组首元素 a[0] 的地址,即 a 等价于 &a[0]。
上述语句定义了整型指针变量 p 和整型数组 a,并使 p 初始指向数组首元素 a[0]。 当指针变量和数组元素建立联系后,可通过以下三种方式访问数组元素。
1) 直接访问:数组名[下标]; 的形式。如 a[3]。
2) 间接访问:*(数组名+i); 的形式。其中,i 为整数,其范围为:0<i<N,N 为数组大小。数组名 a 为首元素的地址,是地址常量,a+i 表示跳过 i 个数据元素的存储空间,即(a+i)表示 a[i] 元素的地址,从而 *(a+i) 表示 a[i]。
如果指针变量 p 被初始化为 a 之后,不再改变,那么也可以使用 *(p + i) 的形式访问 a[i],不过这样就失去了使用指针变量访问数组元素的意义。
3) 间接访问:*(指针变量);的形式。当执行语句 p=a; 后,可以通过改变 p 自身的值(可通过自增、自减运算),从而使得 p 中保存不同的数组元素的地址,进而通过 *p 访问该数组中不同的元素。这是使用指针访问数组元素较常用的形式。例如,如下代码通过使用指针变量的移动来遍历输出数组中的每个元素。
- for(p=a;p<a+N;p++)//用p的移动范围控制循环次数
- printf(“%d\t“,*p);
确定 p 指针移动的起止地址,即循环控制表达式的确定是使用指针访问数组元素的关键。
p 初始指向 a[0],即 p=&a[0]; 或 p=a;。
p 终止指向 a[N-1],即 p=&a[N-l]; 或 p=a+N-1;。
故可得 p 的移动范围为:p>=a && p<=a+N-1;,而 p<=a+N-1 通常写成 p<a+N;,由此可得循环条件为:for (p=a;p<a+N;p++)。
数组名 a 和指针变量 p 的使用说明如下。有如下代码:
- int*p,a[10],i;
- p=a;
1) 执行p=a; 后,*(a+i) 与 *(p+i) 等价,均表示 a[i]。
2) p[i] 与 a[i] 等价。a 为地址值,可采用 a[i] 形式访问数组元素,而 p 也为地址值,故也可采用 p[i] 形式访问数组元素。
3) a 为常量地址,其值不能改变,故 a++; 语法错误。而 p 为变量,其自身的值可以改变,故 p++; 正确。
【例 1】通过指针变量实现对数组元素的输入和输出操作。
实现代码为:
- #include<stdio.h>
- #define N 10
- intmain(void)
- {
- int*p,a[N],i;
- p=a;//p初始指向a[0]
- printf(“Input the array:\n“);
- for(i=0;i<N;i++)//用整型变量i控制循环次数
- scanf(“%d”,p++);//指针P表示地址,不能写成&P
- printf(“the array is :\n“);
- for(p=a;p<a+N;p++)//用p的移动范围控制循环次数
- printf(“%d\t“,*p);
- return0;
- }
补充说明:
输入输出循环控制方法有多种,不管采用哪种,必须准确确定起点和终点的表达式。
1) 输入若采用p的移动范围确定循环次数,则代码如下。
- for(p=a;p<a+N;p++)
- scanf(“%d”,p);
这时,for 语句之前的 p=a; 语句可以去掉。
2) 输出若采用移动指针变量 p 控制循环的执行,因为执行完输入操作后,p 已不再指向数组首元素,而是越界的 a[N] 初始位置,故必须重新给 p 赋值,让其指向数组的首元素, 代码如下。
- p=a;//重新赋值,让p指向数组首元素
- for(i=0;i<N;i++)
- printf(“%d\t“,*p++);
指针值加 1 与地址值加 1 的区别如下。
一般地址单元也称内存单元,是按字节划分的,即地址值加 1,表示跳过一个字节的内存空间。
在 C 语言中,指针变量加 1 表示跳过该指针变量对应基类型所占字节数大小的空间。
在 VC++ 6.0 中,整型占 4 个字节,故对于整型指针变量来说,指针值加 1 对应地址值加 4,即跳过 4 个字节;字符型占 1 个字节,故字符型指针变量加 1,对应地址值也加 1,即跳过 1 个字节。double 型占 8 个字节,故 double 型指针变量加 1,对应地址值加 8,即跳过 8 个字节等。
二维数组和指针
二维数组的逻辑结构为行列形式,但二维数组的存储结构为顺序形式。即二维数组中的数据元素在内存中的存储地址是连续的,故可以使用指针变量保存各个元素的地址值,进而可以间接访问二维数组中的各元素。
例如:
- #define M 3
- #define N 4
- int a[M][N],*p,i,j;
上述语句定义了一个二维整型数组 a、整型指针变量 p 及整型变量 i 和 j。
访问二维数组中的元素,目前可有如下两种方法:
- 使用行列下标,直接访问,即 a[i][j] 形式。如 a[2][3] 表示 2 行 3 列数组元素。
- 通过地址,间接访问,即 *(*(a+i)+j) 形式。
M 行 N 列的二维数组 a,可以看成是含有 a[0]、a[1]、…、a[M-1] 等 M 个元素(M 行)的特殊一维数组,其每个元素 a[i](每行)又是一个含有 N 个元素(N 列)的一维数组。
由于 a[i] 可看成是“一维”数组 a的元素,而 a 可看成该“一维”数组的数组名。根据一维数组元素和一维数组名的关系可得:a[i] 等价于 *(a+i),均表示 i 行的首地址。
而 i 行又含有 N 个元素(N 列),即 a[i][0]、a[i][1]、a[i][2]、…、a[i][j]、…、a[i][N-1]。故 a[i] 表示i行对应一维数组的数组名。由于一维数组名 a[i] 即首元素 a[i][0] 的地址,即 a[i] 等价于 &a[i][0],用 <–> 表示等价,则有以下关系:
- i 行首元素地址:a[i] + 0 <–> *(a + i) +0 <–>&a[i][0]
- i 行 1 列元素地址:a[i] + 1 <–> *(a + i) +1<–>&a[i][1]
- i 行 2 列元素地址:a[i] + 2 <–> *(a + i) +2<–>&a[i][2]
- i 行 j 列元素地址:a[i] + j <–> *(a + i) + j <–>&a[i][j]
地址即指针,通过间接访问符 *,可以访问指针所指空间。即可得访问二维数组元素 a[i][j] 的几种等价形式如下。
*(a[i] + j) <–> *(*(a + i) + j) <–>*&a[i][j]<–>a[i][j]
【例 3】分析如下程序的运行结果,理解二维数组元素 a[i][j] 及其对应地址的各种等价表示形式。
- #include<stdio.h>
- #define M 3
- #define N 4
- intmain(void)
- {
- int*p,a[M][N]={{1,2,3,4},{5,6,7,8},{9,10,11,12}};
- p=&a[0][0];
- printf(“The address of different rows:\n“);
- printf(“a + 0 = %p\n“,a);
- printf(“a + 1 = %p\n“,a +1);
- printf(“a + 2 = %p\n\n“,a +2);
- printf(“The same address:\n“);
- printf(“a[2] + 1 = %p\n“,a[2]+1);
- printf(“*(a+2) +1 = %p\n“,*(a +2)+1);
- printf(“&a[2][1] = %p\n\n“,&a[2][1]);
- printf(“The same element:\n“);
- printf(“*(a[1] + 3) = %d\n“,*(a[1]+3));
- printf(“*(*(a + 1) + 3) = %d\n“,*(*(a +1)+3));
- printf(“a[1][3] = %d\n“, a[1][3]);
- return0;
- }
程序某次的运行结果为:
The address of different rows:
a + 0 = 0060FEDC
a + 1 = 0060FEEC
a + 2 = 0060FEFC
The same address:
a[2] + 1 = 0060FF00
*(a+2) +1 = 0060FF00
&a[2][1] = 0060FF00
The same element:
*(a[1] + 3) = 8
*(*(a + 1) + 3) = 8
a[1][3] = 8
数组指针和指针数组
数组指针
数组指针,即指向一维数组的指针。
数组指针的定义格式为:
类型 (*指针名)[N]; //N元素个数
数组指针是指向含 N 个元素的一维数组的指针。由于二维数组每一行均是一维数组,故通常使用指向一维数组的指针指向二维数组的每一行。例如:
- int(*p)[5];
上述语句表示定义了一个指向一维数组的指针 p,或者简称为一维数组指针 p,该指针 p 只能指向含 5 个元素的整型数组。
在定义数组指针时,如果漏写括号 (),即误写成如下定义形式:
- int*p[5];
由于下标运算符 [] 比 * 运算符的优先级髙,p 首先与下标运算符 [] 相结合,说明 p 为数组,该数组中有 5 个元素,每个为 int * 型。即 p 为指针数组。
二维数组 a[M][N] 分解为一维数组元素 a[0]、a[1]、…、a[M-1] 之后,其每一行 a[i] 均是一个含 N 个元素的一维数组。如果使用指向一维数组的指针来指向二维数组的每一行,通过该指针可以较方便地访问二维数组中的元素。
使用数组指针访问二维数组中的元素。
例如:
- #define M 3
- #define N 4
- int a[M][N],i,j;
- int(*p)[N]=a;// 等价于两条语句 int (*p)[N] ; p=a;
以上语句定义了 M 行 N 列的二维整型数组 a 及指向一维数组(大小为 N)的指针变量 p,并初始化为二维数组名 a,即初始指向二维数组的 0 行。
i 行首地址与 i 行首元素地址的区别如下。
- i 行首元素的地址,是相对于 i 行首元素 a[i][0] 来说的,把这种具体元素的地址,称为一级地址或一级指针,其值加 1表 示跳过一个数组元素,即变为 a[i][1] 的地址。
- i 行首地址是相对于 i 行这一整行来说的,不是具体某个元素的地址,是二级地址,其值加 1 表示跳过 1 行元素对应的空间。
- 对二级指针(某行的地址)做取内容操作即变成一级指针(某行首元素的地址)。
两者的变换关系为:
*(i 行首地址)=i 行首元素地址
0 行首地址:p + 0 <–> a + 0
1 行首地址:p + 1 <–> a + 1
…
i 行首地址:p + i <–> a + i
i 行 0 列元素地址:*(p + i) +0 <—> *(a + i) +0 <—>&a[i][0]
i 行 1 列元素地址:* (p + i) +1 <–> *(a + i) +1 <—>&a[i][1]
…
i 行 j 列元素地址:* (p + i) + j <–> * (a + i) + j <–> &a[i][j]
i 行 j 列对应元素:* (* (p + i) + j) <–> * (* (a + i) + j) <–> a[i][j]
由此可见,当定义一个指向一维数组的指针 p,并初始化为二维数组名 a 时,即 p=a;, 用该指针访问元素 a[i][j] 的两种形式 *(*(p + i) + j) 与 *(*(a + i) + j) 非常相似,仅把 a 替换成了 p 而已。
由于数组指针指向的是一整行,故数组指针每加 1 表示跳过一行,而二维字符数组中每一行均代表一个串,因此在二维字符数组中运用数组指针能较便捷地对各个串进行操作。
指针数组
指针数组,即存储指针的数组,数组中的每个元素均是同类型的指针。
指针数组的定义格式为:
类型 *数组名[数组大小];
例如,如下语句定义了一个含有 5 个整型指针变量的一维数组。
- int* a[5];
数组 a 中含有 5 个元素,每个元素均是整型指针类型。
可以分别为数组的各个元素赋值,例如:
- int a0,a1,a2,a3,a4;
- a[0]=&a0;
- a[1]=&a1;
- …
- a[4]=&a4;
也可以使用循环语句把另一个数组中每个元素的地址赋给指针数组的每个元素。例如:
- int i,*a[5],b[]={1,2,3,4,5};
- for(i=0;i<5;i++)
- a[i]=&b[i];
这样指针数组 a 中每个元素 a[i] 中的值,均为 b 数组对应各元素的地址 &b[i],即整型指针。由于 a[i]=&b[i],两边同时加取内容运算符 *,即 *a[i]=*&b[i]=b[i],即通过指针数组中的每个元素 a[i] 可间接访问 b 数组。如下程序可以输出 b 数组中的所有元素。
- for(i=0;i<5;i++)
- printf(“%d\t“,*a[i]);//*a[i]=b[i]
指针数组最主要的用途是处理字符串。在 C 语言中,一个字符串常量代表返回该字符串首字符的地址,即指向该字符串首字符的指针常量,而指针数组的每个元素均是指针变量,故可以把若干字符串常量作为字符指针数组的每个元素。通过操作指针数组的元素间接访问各个元素对应的字符串。例如:
- char* c[4]={“if”,“else”,“for”,“while”};
- int i;
- for(i=0;i<4;i++)//需确定数组元素个数
- puts(c[i]);//输出c[i]所指字符串
上述方法需要知道数组元素个数即该数组中字符串的个数。更通常的做法是,在字符指针数组的最后一个元素(字符串)的后面存一个 NULL 值。NULL 不是 C 语言的关键字,在 C 语言中 NULL 为宏定义:
- #defineNULL((void*)0)
NULL 在多个头文件中均有定义,如 stdlib.h、stdio.h、string.h、stddef.h等。只要包含上述某个头文件,均可以使用 NULL。
上述语句可以修改为:
- char*c[]={“if”,“else”,“for”,“while”, NULL};
- int i;
- for(i=0;c[i]!=NULL;i++)//NULL 代替使用数组大小
- puts(c[i]);
指针与字符串
常量字符串与指针
1) 字符串与字符指针常量
字符串常量返回的是一个字符指针常量,该字符指针常量中保存的是该字符串首字符的地址,即指向字符串中第一个字符的指针。
例如,字符串常量 “abcd” 表示一个指针,该指针指向字符 ‘a’,表达式 “abcd”+1,是在指针 “abcd” 值的基础上加 1,故也是一个指针,指向字符串中第二个字符的指针常量。同理,”abcd”+3 表示指向第 4 个字符 ‘d’ 的指针常量。
由于 “abcd”+1 表示指向字符 ‘b’ 的指针常量,即保存 ‘b’ 的地址,故如下两条语句均是输出从该指针地址开始直到遇到字符串结束符 ‘\0’ 为止的字符串 “bcd”。
- puts(“abcd”+1);
等价于
- printf(“%s\n“,“abcd”+1);
既然字符串返回指针,那么通过间接访问符 *,可以访问该指针所指向的字符,例如: *(“abcd”+1) 表示字符 ‘b’; *(“abcd”+3) 表示字符 ‘d’; *(“abcd”+4) 表示空字符 ‘\0’; *(“abcd”+5) 已越界,表示的字符不确定。
所以,以下两条语句均输出字符 ‘c’。
- putchar(*(“abcd”+2));//输出字符
- printf(“%c”,*(“abcd”+2));//输出字符’c’
以下语句输出空字符(字符串结束符)。
- putchar(*(“abcd”+4));//输出字符串结束符空字符
由于 “abcd”+5 表示的指针已超出字符串存储空间,该指针指向的内容 *(“abcd”+5) 不确定。
- putchar(*(“abcd”+5));//禁止使用。其值不确定
当字符数组名用于表达式时也是作为字符指针常量的,例如:
- char c[]=“xyz”;
数组名 c 为指针常量,即字符的地址,故 c+1 为字符 ‘y’ 的地址,故如下语句输出 yz。
- puts(c+1);//输出yz并换行
字符串和字符数组名均表示指针常量,其本身的值不能修改。如下语句均是错误的。
- c++; //错误。字符数组名c为常量
- “xyz”++;//错误。字符串表示指针常量,其值不能修改
- *(“xyz”+1)=‘d’;//运行时错误。试图把y,变为W
2) 字符串与字符指针变量
在 C 语言中,经常定义一个字符指针变量指向一个字符串,例如:
- char*pc=“abcd”;
定义了一个字符指针变量 pc,并初始化为字符串 ”abcd”,即初始指向字符串的首字符,pc=pc+1; 表示向后移动一个字符单元,pc 保存字符 ‘b’ 的地址,即指向字符 1。通过每次使 pc 增 1,可以遍历字符串中的每个字符。
例如,如下代码段通过指针变量依次遍历输出所指串中每个字符。
程序代码为:
- #include<stdio.h>
- intmain(void)
- {
- //初始指向首字符
- //间接访问所指字符 //pc依次指向后面的字符
- char*pc=“hello,world!”;
- while(*pc!=‘\0‘)
- {
- putchar(*pc);
- pc++;
- }
- return0;
- }
通过字符指针变量可访问所指向的字符串常量,但仅限于“读取”操作,也可以修改字符指针变量的指向,即让其重新指向其他字符串;但不能进行“修改”操作,即不能通过该指针变量,企图改变所指向字符串的内容。有些编译器在编译时可能不报错,但运行时会发生错误。例如:
- char*pc;//正确,未初始化,随机指向
该语句定义了一个字符指针变量,并未显式初始化,属于“野”指针,不能对该指针所指内容进行存取操作。由于 pc 为变量,故可以修改指针的指向,即可以让指针变量 pc 重新指向其他字符串。故如下操作是正确的。
- pc=“abcd”;//正确,让 pc 指向串 “abcd”
- pc=“hello”;//正确,修改pc指向,让其指向串”hello”
此时,字符指针变量 pc 已指向字符串常量 “hello”,不能通过指针修改该字符串常量。 如下操作是错误的。
- *(pc+4)=‘p’;//运行时错误。试图把’o’字符改变为’p’
更不允许企图通过 pc 指针,覆盖其所指字符串常量。如下企图使用 Strcpy 把 “xyz” 串复制并覆盖 pc 所指串 “hello”。
- strcpy(pc,“xyz”);//运行时错误。企图把另一个串复制到pc空间
变量字符串
字符数组可以理解为若干个字符变量的集合,如果一个字符串存放在字符数组中,那么字符串中的每个字符都相当于变量,故该字符串中的每个字符均可以改变,故可把存放在字符数组中的字符串称为变量字符串。
1) 字符数组空间分配 例如:
- char str[10]=“like”;
定义了一个字符数组并显式指定其大小是 10(数组空间应足够大,一般大于等于字符串长度 +1),即占 10 个字符空间,前 5 个空间分别存放有效字符 ‘l’,’i’,’k’,’e’ 及结束符 ‘\0’,多余的空间均用 ‘\0’ 填充。
定义时也可以不显式指定其大小,让编译器根据初始化字符串长度加 1 来自动分配空间大小。例如:
- char s[]=“like”;
编译器为该数组分配 5 个字符空间大小,前 4 个为有效字符第 5 个为结束符 ‘\0’。
2) 访问字符数组元素
使用数组下标的形式可以逐个改变数组中的每个元素,如下所示。
- s[1]=*o‘; //正确。
- s[2] =’v‘;; //正确。’k‘->’v‘
- puts (s); //输出love并换行
可以把字符数组和字符指针联合使用,如下所示。
- char str[]=‘I Like C Language!”;
- char *ps=str;//初始指向字符串首字符”I”
- *(ps+3)=’o‘;//’i‘->’o‘
- *(ps+4)=’v‘;//’k‘->’v‘
- ps=str+2;//ps指向’L‘字符
- puts (ps);//输出 Love C Language!并换行
3) 字符数组访问越界
不管采用数组名加下标形式还是使用字符指针变量访问字符串,一定不能越界。否则可能会产生意想不到的结果,甚至程序崩溃。如下操作均是错误的。
- char c[]=“Nan Jing”,*pc=c+4;//c 大小:9,pc 指向’J’
- c[10]=‘!’;//错误。没有c[10]元素,越界存储,编译器不检查数组是否越界
- *(pc+6)=‘!’;//错误。越界存,pc+6 等价于 c[10]
- putchar(c[9]);//错误,越界取,值不确定
4) 字符串结束符
一般把字符串存放于字符数组中时,一定要存储字符串结束符 ‘\0’,因为 C 库函数中,对字符串处理的函数,几乎都是把 ‘\0’ 作为字符串结束标志的。如果字符数组中没有存储结束符,却使用了字符串处理函数,因为这些函数会寻找结束符 ‘\0’,可能会产生意想不到的结果,甚至程序崩溃。例如:
- char s1[5]=“hello”;//s1不含’\0′
- char s2[]={‘w’,‘o’,‘r’,‘l’,‘d’};//s2大小:5,不含’\0′
- char s3[5];//未初始化,5个空间全为不确定值
- s3[0]=‘g’;
- s3[1]=‘o’;
s3 数组的前两个空间被赋值为 ‘g’ 和 ‘o’,未被显式赋值的 s3[2]、s3[3]、s3[4] 依然为不确定值。即 s3 数组中依然不含有字符串结束符 ‘\0’。s3 数组各元素如下所示(’?’表示不确定值)。
| s3[0] | s3[1] | s3[2] | s3[3] | s3[4] |
|---|---|---|---|---|
| g | o | ? | ? | ? |
故以下操作语句严格来说均是错误的,是被禁止的操作。
- puts(s2);//s2中不含’\0’,输出不确定值,甚至程序崩溃.
- strcpy(s1, s3);//运行时错误。s3中找不到结束符’\0′
注意 s3 数组与如下 s4 数组的区别。
- char s4[5]={‘g’,‘o’};
s4 数组中有 5 个元素,初始化列表中显式提供了两个字符 ‘g’ 和 ‘o’,其他元素使用字符的默认值:空字符,即结束符 ‘\0’。s4 数组各元素如下所示。
| s4[0] | s4[1] | s4[2] | s4[3] | s4[4] |
|---|---|---|---|---|
| g | o | \0 | \0 | \0 |
故对 s4 数组的如下操作语句均是正确的。
- puts(s4);//输出go并换行
- strcpy(s1,s4);//把 s4 中的串 go 和一个’\o’复制到 s1 中。
执行上述语句后,s1 数组中各元素如下所示。
| s1[0] | s1[1] | s1[2] | s1[3] | s1[4] |
|---|---|---|---|---|
| g | o | \0 | 1 | o |
此时,s1 数组中也含有字符串结束符。可以调用字符串处理函数(第一次遇到 ‘\0’ 表示一个串结束),如下所示。
- int len=strlen(s1);// 正确,len 为 2
- puts(s1);//正确,输出go并换行
5) 通过字符指针修改变量字符串
通过字符指针变量可以访问所指字符数组中保存的串,不仅可以读取该数组中保存的字符串,还可以修改该串的内容。原因从数组的本质上理解:数组是一系列相同类型变量的集合,故其中保存的字符串,可以理解为是由若干个字符变量组成的。每个字符变量当然可以改变。
例如:
- #include<stdio.h>
- #include<string.h>
- intmain(void)
- {
- char str[30]=“Learn and live.”
- *p=str;
- *(p+6)=‘A’;
- *(p+10)=‘L’;
- puts(str);
- return0;
- }
该程序中,字符指针 p 指向数组 str 中的字符串,由于该字符串是由一系列字符变量组成的,故通过指针变量 p 可以改变该字符串中的字符。故该程序输出:Learn And Live.。
指针与函数
指针作函教形参——传址调用
在函数章节中,讲述了函数调用的两种形式:传值调用和传址调用,其中,传址调用介绍的是数组类型作函数形参,数组名作实参的形式。
现在介绍传址调用的另外一种形式,即指针变量作函数形参,地址(或其他指针变量)作实参的形式。函数调用时,在函数体内可以通过实参地址间接地对该实参地址对应的空间进行操作,从而实现可以在函数体内改变外部变量值的功能。
传值调用与传址调用的区别如下:
- 传值调用:实参为要处理的数据,函数调用时,把要处理数据(实参)的一个副本复制到对应形参变量中,函数中对形参的所有操作均是对原实参数据副本的操作,无法影响原实参数据。且当要处理的数据量较大时,复制和传输实参的副本可能浪费较多的空间和时间。
- 传址调用:顾名思义,实参为要处理数据的地址,形参为能够接受地址值的“地址箱”即指针变量。函数调用时,仅是把该地址传递给对应的形参变量,在函数体内,可通过该地址(形参变量的值)间接地访问要处理的数据,由于并没有复制要处理数据的副本,故此种方式可以大大节省程序执行的时间和空间。
指针作函教返回类型——指针函教
有时函数调用结束后,需要函数返回给调用者某个地址即指针类型,以便于后续操作,这种函数返回类型为指针类型的函数,通常称为指针函数。
指针函数的定义格式为:
类型*函数名(形参列表)
{
… /*函数体*/
}
指针函数,在字符串处理函数中尤为常见。
例如,编程实现把一个源字符串 src 连接到目标字符串 dest 之后的函数,两串之间用空格隔开,并返回目标串 dest 的地址。
实现代码为:
- #include<stdio.h>
- char*str_cat(char* dest,char* src);
- intmain(void)
- {
- char s1[20]=“Chinese”;//目标串
- char s2[10]=“Dream”;
- char*p=str_cat(s1, s2);//返回地址赋给 p
- puts(p);
- return0;
- }
- //str_cat的参数也可为字符数组形式
- char*str_cat(char* dest,char* src)
- {
- char*p1=dest,*p2=src;
- while(*p1!=‘\0‘)//寻找dest串的结尾,循环结束时,p1指向’\0T字符
- p1++;
- *p1++=‘ ‘;//加空格,等价于*p1=”;p1++;
- while(*p2!=‘\0‘)
- *p1++=*p2++;
- return dest;
- }
运行结果:
Chinese Dream
指向函教的指针——函教指针
在 C 语言中,整型变量在内存中占一块内存空间,该空间的起始地址称为整型指针,可把整型指针保存到整型指针变量中。函数像其他变量一样,在内存中也占用一块连续的空 间,把该空间的起始地址称为函数指针。而函数名就是该空间的首地址,故函数名是常量指针。可把函数指针保存到函数指针变量中。
1) 函数指针的定义
函数指针变量的定义格式为:
返回类型(*指针变量名)(函数参数表);
说明:上述定义中,指针变量名定义括号不能省略,否则,则为返回指针类型的函数原型声明,即指针函数的声明。
例如:
- int*pf(int,int);//该语句声明了一个函数原型,该函数名为pf,该函数含两个int型参数,且该函数返回类型为整型指针类型,即int*。
- int(*pf)(int,int);//该语句定义了一个函数指针变量pf,该指针变量pf可以指向任意含有两个整型参数,且返回值为整型的函数。
如下定义了一个func函数。
- intfunc(int a,int b)
- {
- //…
- }
该函数含有两个整型参数,且返回类型为整型。与 pf 要求指向的函数类型一致,可让 pf 指向该函数,可以采用如下两种方式。
- pf=&func;//正确
- pf=func;//正确。也可省略&
在给函数指针变量赋值时,函数名前面的取地址操作符 & 可以省略。因为在编译时,C 语言编译器会隐含完成把函数名转换成对应指针形式的操作,故加 & 只是为了显式说明编译器隐含执行该转换操作。
有如下三个函数的原型声明:
- voidf1(int);
- intf2(int,float);
- charf3(int,int);
可能有些编译器对类型检查不严格,但严格意义上来说,如下对函数指针的赋值语句均认为是错误的。
- pf=f1;//错误。参数个数不一致、返回类型不一致
- pf=f2;//错误。参数2的类型不一致
- pf=f3;//错误。返回类型不一致
2) 通过函数指针调用函数
例如,如下 f() 函数原型及函数指针变量 pf:
- intf(int a);
- int(*pf)(int)=&f;//正确。pf 初始指向 f()函数
当函数指针变量 pf 被初始化指向函数f()后,调用函数 f() 有如下三种形式。
- int result;
- result=f(2);//正确。编译器会把函数名转换成对应指针
- result=pf(2);//正确。直接使用函数指针
- result=(*pf)(2);//正确。先把函数指针转换成对应函数名
函数调用时,编译器把函数名转换为对应指针形式,故前两种调用方式含义一样,而第三种调用方式,*pf 转换成对应的函数名 f(),编译时,编译器还会把函数名转换成对应指针形式,从这个角度来理解,第三种调用方式走了些弯路。
函数指针通常主要用于作为函数参数的情形。
假如实现一个简易计算器,函数名为 cal(),假设该计算器有加减乘除等基本操作,每个操作均对应一个函数实现,即有 add()、sub ()、mult()、div() 等,这 4 个函数具有相同的参数及返回值类型。即:
- intadd(int a,int b);//加操作
- intsub(int a,int b);//减操作
- intmult(int a,int b);//乘操作
- intdiv(int a,int b);//除操作
定义函数指针变量 int (*pf) (int,int);,该函数指针变量 pf 可分别指向这 4 个函数。
如果用户调用该计算器函数 cal(),希望在不同的时刻调用其不同的功能(加减乘除),较通用的方法,是把该函数指针变量作为计算器函数 cal() 的参数。即:
- //计算器函数
- voidcal(int(*pf)(int,int),int op1,int op2)
- {
- pf(op1,op2);//或者(*pf) (op1,op2);
- }
假如当用户希望调用 cal() 函数实现加操作时,只需把加操作函数名 add() 及加数和被加数作为实参传给 cal () 函数即可;此时 pf 指针指向 add() 函数,在 cal () 函数内通过该函数指针变量 pf 调用其所执行的函数 add ()。可采用如下两种调用方式。
- pf(op1,op2);
或者
- (*pf)(op1,op2);
例如,使用函数指针,编程实现一个简单计算器程序。实现代码为:
- #include<stdio.h>
- voidcal(void(*pf)(int,int),int opl,int op2);
- voidadd(int a,int b);//加操作
- voidsub(int a,int b);//减操作
- voidmult(int a,int b);//乘操作
- intmain(void)
- {
- int sel,x1,x2;
- printf(“Select the operator:”);
- scanf(“%d”,&sel);
- printf(“Input two numbers:”);
- scanf(“%d%d”,&x1,&x2);
- switch(sel)
- {
- case1:
- cal(add,x1,x2);
- break;
- case2:
- cal(sub,x1,x2);
- break;
- case3:
- cal(mult,x1,x2);
- break;
- default:
- printf(“Input error!\n“);
- }
- return0;
- }
- voidcal(void(*pf)(int,int),int opl,int op2)
- {
- pf(opl,op2);//或者(*pf)(opl,op2);
- }
- voidadd(int a,int b)
- {
- int result=(a + b);
- printf(“%d + %d = %d\n“,a,b,result);
- }
- voidsub(int a,int b)
- {
- int result=(a – b);
- printf(“%d – %d = %d\n“, a,b, result);
- }
- voidmult(int a,int b)
- {
- int result=(a * b);
- printf(“%d * %d = %d\n“,a,b,result);
- }
运行结果为:
Select the operator:1
Input two numbers:2 5
2 + 5 = 7
与其他高级编程语言相比,C 语言可以更高效地对计算机硬件进行操作,而计算机硬件的操作指令,在很大程度上依赖于地址。
指针提供了对地址操作的一种方法,因此,使用指针可使得 C 语言能够更高效地实现对计算机底层硬件的操作。另外,通过指针可以更便捷地操作数组。在一定意义上可以说,指针是 C 语言的精髓。
内存与地址
在计算机中,数据是存放在内存单元中的,一般把内存中的一个字节称为一个内存单元。为了更方便地访问这些内存单元,可预先给内存中的所有内存单元进行地址编号,根据地址编号,可准确找到其对应的内存单元。由于每一个地址编号均对应一个内存单元,因此可以形象地说一个地址编号就指向一个内存单元。C 语言中把地址形象地称作指针。
C语言中的每个变量均对应内存中的一块内存空间,而内存中每个内存单元均是有地址编号的。在 C 语言中,可以使用运算符 & 求某个变量的地址。
例如,在如下代码中,定义了字符型变量 c 和整型变量 a,并分别赋初值 ‘A’ 和 100。
- #include<stdio.h>
- intmain(void)
- {
- char c=‘A’;
- int a=100;
- printf(“a=%d\n“,a);//输出变量a的值
- printf(“&a=%x\n“,&a);//输出变量a的地址
- printf(“c=%c\n“,c);
- printf(“&c=%x\n“,&c);
- return0;
- }
程序某次的运行结果为:
a=100
&a=12ff40
c=A
&c=12ff44
分析:
在 C 语言中,字符型变量占一个字节的内存空间,而整型变量所占字节数与系统有关。例如,在 32 位系统中,VC++6.0 开发环境中,int 型占 4 个字节。假设程序在某次运行时,变量 a 和 c 在内存中的分配情况如图 1 所示:内存单元(每个字节)的地址编号分别为十六进制表示的 …12ff40、12ff41、12ff42、12ff43、12ff44…,每个地址编号均为对应字节单元的起始地址。

图 1 变量的值及内存地址
由图 1 可知,变量 a 对应于从地址 12ff40 开始的 4 个字节(12ff40、12ff41、12ff42、12ff43)的内存空间,存储的是整数 100 的 32 位二进制形式(为直观表示,本例并没有转换成二进制形式)。字符型变量 c,对应地址为 12ff44,该地址内存储的是字母对应 ASCII 值的 8 位二进制形式。
语句 printf(“a=%d\n”,a); 输出:a=100。
语句 printf(“&a=%x\n”,&a); 是按十六进制形式输出变量 a 的地址(a 在内存中的起始地址值)为 &a=12ff40。
在上例中,变量 a 和 c 的起始地址 12ff40 和 12ff44 均为指针,分别指向变量 a 和变量 c。
区分变量的地址值和变量的值。如上例中,变量 a 的地址值(指针值)为12ff40,而变量 a 的值为 100。
指针变量的定义
可以保存地址值(指针)的变量称为指针变量,因为指针变量中保存的是地址值,故可以把指针变量形象地比喻成地址箱。
指针变量的定义形式如下。
类型 * 变量名;
例如:
- int*pa;
定义了一个整型指针变量 pa,该指针变量只能指向基类型为 int 的整型变量,即只能保存整型变量的地址。
说明:
1) *号标识该变量为指针类型,当定义多个指针变量时,在每个指针变量名前面均需要加一个 *,不能省略,否则为非指针变量。例如:
- int*pa,*pb;
表示定义了两个指针变量 pa、pb。而:
int *pa,pb;
则仅有 pa 是指针变量,而 pb 是整型变量。
- int*pi,a,b;//等价于inta,b,*pi;
表示定义了一个整型指针变量 pi 和两个整型变量 a 和 b。
2) 在使用已定义好的指针变量时,在变量名前面不能加 *。例如:
- int*p,a;
- *p=&a;//错误,指针变量是p而不是*p
而如下语句是正确的。
- int a,*p=&a;//正确
该语句貌似把 &a 赋给了 *p,而实际上 p 前的 * 仅是定义指针变量 p 的标识,仍然是把 &a 赋给了 p,故是正确的赋值语句。
3) 类型为该指针变量所指向的基类型,可以为 int、char、float 等基本数据类型,也可以为自定义数据类型。
该指针变量中只能保存该基类型变量的地址。
假设有如下变量定义语句:
- int a,b,*pa,*pb;
- char*pc,c;
则:
- pa=&a;//正确。pa基类型为int,a为int型变量,类型一致
- pb=&c;//错误。pb基类型为int,c为char型变量,类型不一致
- pc=&c;//正确。pc基类型为char,c为char型变量,类型一致
- *pa=&a;//错误。指针变量是pa而非*pa
4) 变量名是一合法标识符,为与普通变量相区分,一般指针变量名以字母 p(pointer)开头,如 pa、pb 等。
5) 由于是变量,故指针变量的值可以改变,也即可以改变指针变量的指向。
- char c1,*pc,c2;//定义了字符变量c1、c2和字符指针变量pc
则如下对指针变量的赋值语句均是正确的。
- pc=&c1;//pc指向c1
- pc=&c2;//pc不再指向c1,而指向c2
6) 同类型的指针变量可以相互赋值。
- int a,*p1,*p2,b;//定义了两个整型变量a,b;两个整型指针变量为p1,p2
- float*pf;
以下赋值语句均是正确的。
- p1=&a;//地址箱p1中保存a的地址,即p1指向a
- p2=p1;//p2也指向a,即p1和p2均指向a
上述最后一条赋值语句相当于把地址箱 p1 中的值赋给地址箱 p2,即 p2 中也保存 a 的地址,即和 p1 —样,p2 也指向变量 a。
以下赋值语句均是错误的。
- pf=p1; //错误。p1,pf虽然都是指针变量,但类型不同,不能赋值
- pf=&b;//错误。指针变量pf的基类型为float,b类型为int,不相同
由于指针变量是专门保存地址值(指针)的变量,故本节把指针变量形象地看成“地址箱”。
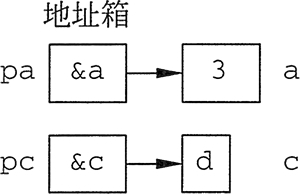
设有如下定义语句:
- int a=3,*pa=&a;//pa保存变量a的地址,即指向a
- char c=‘d’,*pc=&c;//pc保存变量c的地址,即指向c
把整型变量 a 的地址赋给地址箱 pa,即 pa 指向变量 a,同理 pc 指向变量 c,如图 2 所示。
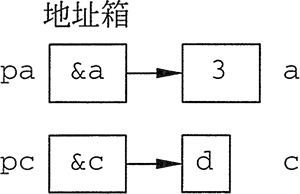
图 2 指针指向变量
指针变量的引用
访问内存空间,一般分为直接访问和间接访问。
如果知道内存空间的名字,可通过名字访问该空间,称为直接访问。由于变量即代表有名字的内存单元,故通。过变量名操作变量,也就是通过名字直接访问该变量对应的内存单元。
如果知道内存空间的地址,也可以通过该地址间接访问该空间。对内存空间的访问操作一般指的是存、取操作,即向内存空间中存入数据和从内存空间中读取数据。
在 C 语言中,可以使用间接访问符(取内容访问符)*来访问指针所指向的空间。
例如:
- int*p,a=3;//p中保存变量a对应内存单元的地址
- p=&a;
在该地址 p 前面加上间接访问符 *,即代表该地址对应的内存单元。而变量 a 也对应该内存单元,故 *p 就相当于 a。
- printf(“a=%d\n“,a);//通过名字,直接访问变量a空间(读取)
- printf(“a=%d\n“,*p);//通过地址,间接访问变量a空间(读取)
- *p=6;//等价于a=6;间接访问a对应空间(存)
“野”指针
本节中,把没有合法指向的指针称为“野”指针。因为“野”指针随机指向一块空间,该空间中存储的可能是其他程序的数据甚至是系统数据,故不能对“野”指针所指向的空间进行存取操作,否则轻者会引起程序崩溃,严重的可能导致整个系统崩溃。
例如:
- int*pi,a;//pi未初始化,无合法指向,为“野”指针
- *pi=3;//运行时错误!不能对”野”指针指向的空间做存入操作。该语句试图把 3 存入“野”指针pi所指的随机空间中,会产生运行时错误。
- a=*pi;//运行时错误!不能对”野”指针指向的空间取操作。该语句试图从“野”指针pi所指的空间中取出数据,然后赋给变量a同样会产生运行时错误。
正确的使用方法:
- pi=&a;//让pi有合法的指向,pi指向a变量对应的空间
- *pi=3;//把3间接存入pi所指向的变量a对应的空间
指针与数组
数组是一系列相同类型变量的集合,不管是一维数组还是多维数组其存储结构都是顺序存储形式,即数组中的元素是按一定顺序依次存放在内存中的一块连续的内存空间中(地址连续)。
指针变量类似于一个地址箱,让其初始化为某个数组元素的地址,以该地址值为基准,通过向前或向后改变地址箱中的地址值,即可让该指针变量指向不同的数组元素,从而达到通过指针变量便可以方便地访问数组中各元素的目的。
一维教组和指针
在 C 语言中,指针变量加 1 表示跳过该指针变量对应的基类型所占字节数大小的空间。指向数组元素的指针,其基类型为数组元素类型,指针加 1 表示跳过一个数组元素空间,指向下一个数组元素。
例如:
- int*p,a[10];
- p=a;//相当于 p=&a[0];
说明:数组名 a 相当于数组首元素 a[0] 的地址,即 a 等价于 &a[0]。
上述语句定义了整型指针变量 p 和整型数组 a,并使 p 初始指向数组首元素 a[0]。 当指针变量和数组元素建立联系后,可通过以下三种方式访问数组元素。
1) 直接访问:数组名[下标]; 的形式。如 a[3]。
2) 间接访问:*(数组名+i); 的形式。其中,i 为整数,其范围为:0<i<N,N 为数组大小。数组名 a 为首元素的地址,是地址常量,a+i 表示跳过 i 个数据元素的存储空间,即(a+i)表示 a[i] 元素的地址,从而 *(a+i) 表示 a[i]。
如果指针变量 p 被初始化为 a 之后,不再改变,那么也可以使用 *(p + i) 的形式访问 a[i],不过这样就失去了使用指针变量访问数组元素的意义。
3) 间接访问:*(指针变量);的形式。当执行语句 p=a; 后,可以通过改变 p 自身的值(可通过自增、自减运算),从而使得 p 中保存不同的数组元素的地址,进而通过 *p 访问该数组中不同的元素。这是使用指针访问数组元素较常用的形式。例如,如下代码通过使用指针变量的移动来遍历输出数组中的每个元素。
- for(p=a;p<a+N;p++)//用p的移动范围控制循环次数
- printf(“%d\t“,*p);
确定 p 指针移动的起止地址,即循环控制表达式的确定是使用指针访问数组元素的关键。
p 初始指向 a[0],即 p=&a[0]; 或 p=a;。
p 终止指向 a[N-1],即 p=&a[N-l]; 或 p=a+N-1;。
故可得 p 的移动范围为:p>=a && p<=a+N-1;,而 p<=a+N-1 通常写成 p<a+N;,由此可得循环条件为:for (p=a;p<a+N;p++)。
数组名 a 和指针变量 p 的使用说明如下。有如下代码:
- int*p,a[10],i;
- p=a;
1) 执行p=a; 后,*(a+i) 与 *(p+i) 等价,均表示 a[i]。
2) p[i] 与 a[i] 等价。a 为地址值,可采用 a[i] 形式访问数组元素,而 p 也为地址值,故也可采用 p[i] 形式访问数组元素。
3) a 为常量地址,其值不能改变,故 a++; 语法错误。而 p 为变量,其自身的值可以改变,故 p++; 正确。
【例 1】通过指针变量实现对数组元素的输入和输出操作。
实现代码为:
- #include<stdio.h>
- #define N 10
- intmain(void)
- {
- int*p,a[N],i;
- p=a;//p初始指向a[0]
- printf(“Input the array:\n“);
- for(i=0;i<N;i++)//用整型变量i控制循环次数
- scanf(“%d”,p++);//指针P表示地址,不能写成&P
- printf(“the array is :\n“);
- for(p=a;p<a+N;p++)//用p的移动范围控制循环次数
- printf(“%d\t“,*p);
- return0;
- }
补充说明:
输入输出循环控制方法有多种,不管采用哪种,必须准确确定起点和终点的表达式。
1) 输入若采用p的移动范围确定循环次数,则代码如下。
- for(p=a;p<a+N;p++)
- scanf(“%d”,p);
这时,for 语句之前的 p=a; 语句可以去掉。
2) 输出若采用移动指针变量 p 控制循环的执行,因为执行完输入操作后,p 已不再指向数组首元素,而是越界的 a[N] 初始位置,故必须重新给 p 赋值,让其指向数组的首元素, 代码如下。
- p=a;//重新赋值,让p指向数组首元素
- for(i=0;i<N;i++)
- printf(“%d\t“,*p++);
指针值加 1 与地址值加 1 的区别如下。
一般地址单元也称内存单元,是按字节划分的,即地址值加 1,表示跳过一个字节的内存空间。
在 C 语言中,指针变量加 1 表示跳过该指针变量对应基类型所占字节数大小的空间。
在 VC++ 6.0 中,整型占 4 个字节,故对于整型指针变量来说,指针值加 1 对应地址值加 4,即跳过 4 个字节;字符型占 1 个字节,故字符型指针变量加 1,对应地址值也加 1,即跳过 1 个字节。double 型占 8 个字节,故 double 型指针变量加 1,对应地址值加 8,即跳过 8 个字节等。
二维数组和指针
二维数组的逻辑结构为行列形式,但二维数组的存储结构为顺序形式。即二维数组中的数据元素在内存中的存储地址是连续的,故可以使用指针变量保存各个元素的地址值,进而可以间接访问二维数组中的各元素。
例如:
- #define M 3
- #define N 4
- int a[M][N],*p,i,j;
上述语句定义了一个二维整型数组 a、整型指针变量 p 及整型变量 i 和 j。
访问二维数组中的元素,目前可有如下两种方法:
- 使用行列下标,直接访问,即 a[i][j] 形式。如 a[2][3] 表示 2 行 3 列数组元素。
- 通过地址,间接访问,即 *(*(a+i)+j) 形式。
M 行 N 列的二维数组 a,可以看成是含有 a[0]、a[1]、…、a[M-1] 等 M 个元素(M 行)的特殊一维数组,其每个元素 a[i](每行)又是一个含有 N 个元素(N 列)的一维数组。
由于 a[i] 可看成是“一维”数组 a的元素,而 a 可看成该“一维”数组的数组名。根据一维数组元素和一维数组名的关系可得:a[i] 等价于 *(a+i),均表示 i 行的首地址。
而 i 行又含有 N 个元素(N 列),即 a[i][0]、a[i][1]、a[i][2]、…、a[i][j]、…、a[i][N-1]。故 a[i] 表示i行对应一维数组的数组名。由于一维数组名 a[i] 即首元素 a[i][0] 的地址,即 a[i] 等价于 &a[i][0],用 <–> 表示等价,则有以下关系:
- i 行首元素地址:a[i] + 0 <–> *(a + i) +0 <–>&a[i][0]
- i 行 1 列元素地址:a[i] + 1 <–> *(a + i) +1<–>&a[i][1]
- i 行 2 列元素地址:a[i] + 2 <–> *(a + i) +2<–>&a[i][2]
- i 行 j 列元素地址:a[i] + j <–> *(a + i) + j <–>&a[i][j]
地址即指针,通过间接访问符 *,可以访问指针所指空间。即可得访问二维数组元素 a[i][j] 的几种等价形式如下。
*(a[i] + j) <–> *(*(a + i) + j) <–>*&a[i][j]<–>a[i][j]
【例 3】分析如下程序的运行结果,理解二维数组元素 a[i][j] 及其对应地址的各种等价表示形式。
- #include<stdio.h>
- #define M 3
- #define N 4
- intmain(void)
- {
- int*p,a[M][N]={{1,2,3,4},{5,6,7,8},{9,10,11,12}};
- p=&a[0][0];
- printf(“The address of different rows:\n“);
- printf(“a + 0 = %p\n“,a);
- printf(“a + 1 = %p\n“,a +1);
- printf(“a + 2 = %p\n\n“,a +2);
- printf(“The same address:\n“);
- printf(“a[2] + 1 = %p\n“,a[2]+1);
- printf(“*(a+2) +1 = %p\n“,*(a +2)+1);
- printf(“&a[2][1] = %p\n\n“,&a[2][1]);
- printf(“The same element:\n“);
- printf(“*(a[1] + 3) = %d\n“,*(a[1]+3));
- printf(“*(*(a + 1) + 3) = %d\n“,*(*(a +1)+3));
- printf(“a[1][3] = %d\n“, a[1][3]);
- return0;
- }
程序某次的运行结果为:
The address of different rows:
a + 0 = 0060FEDC
a + 1 = 0060FEEC
a + 2 = 0060FEFC
The same address:
a[2] + 1 = 0060FF00
*(a+2) +1 = 0060FF00
&a[2][1] = 0060FF00
The same element:
*(a[1] + 3) = 8
*(*(a + 1) + 3) = 8
a[1][3] = 8
数组指针和指针数组
数组指针
数组指针,即指向一维数组的指针。
数组指针的定义格式为:
类型 (*指针名)[N]; //N元素个数
数组指针是指向含 N 个元素的一维数组的指针。由于二维数组每一行均是一维数组,故通常使用指向一维数组的指针指向二维数组的每一行。例如:
- int(*p)[5];
上述语句表示定义了一个指向一维数组的指针 p,或者简称为一维数组指针 p,该指针 p 只能指向含 5 个元素的整型数组。
在定义数组指针时,如果漏写括号 (),即误写成如下定义形式:
- int*p[5];
由于下标运算符 [] 比 * 运算符的优先级髙,p 首先与下标运算符 [] 相结合,说明 p 为数组,该数组中有 5 个元素,每个为 int * 型。即 p 为指针数组。
二维数组 a[M][N] 分解为一维数组元素 a[0]、a[1]、…、a[M-1] 之后,其每一行 a[i] 均是一个含 N 个元素的一维数组。如果使用指向一维数组的指针来指向二维数组的每一行,通过该指针可以较方便地访问二维数组中的元素。
使用数组指针访问二维数组中的元素。
例如:
- #define M 3
- #define N 4
- int a[M][N],i,j;
- int(*p)[N]=a;// 等价于两条语句 int (*p)[N] ; p=a;
以上语句定义了 M 行 N 列的二维整型数组 a 及指向一维数组(大小为 N)的指针变量 p,并初始化为二维数组名 a,即初始指向二维数组的 0 行。
i 行首地址与 i 行首元素地址的区别如下。
- i 行首元素的地址,是相对于 i 行首元素 a[i][0] 来说的,把这种具体元素的地址,称为一级地址或一级指针,其值加 1表 示跳过一个数组元素,即变为 a[i][1] 的地址。
- i 行首地址是相对于 i 行这一整行来说的,不是具体某个元素的地址,是二级地址,其值加 1 表示跳过 1 行元素对应的空间。
- 对二级指针(某行的地址)做取内容操作即变成一级指针(某行首元素的地址)。
两者的变换关系为:
*(i 行首地址)=i 行首元素地址
0 行首地址:p + 0 <–> a + 0
1 行首地址:p + 1 <–> a + 1
…
i 行首地址:p + i <–> a + i
i 行 0 列元素地址:*(p + i) +0 <—> *(a + i) +0 <—>&a[i][0]
i 行 1 列元素地址:* (p + i) +1 <–> *(a + i) +1 <—>&a[i][1]
…
i 行 j 列元素地址:* (p + i) + j <–> * (a + i) + j <–> &a[i][j]
i 行 j 列对应元素:* (* (p + i) + j) <–> * (* (a + i) + j) <–> a[i][j]
由此可见,当定义一个指向一维数组的指针 p,并初始化为二维数组名 a 时,即 p=a;, 用该指针访问元素 a[i][j] 的两种形式 *(*(p + i) + j) 与 *(*(a + i) + j) 非常相似,仅把 a 替换成了 p 而已。
由于数组指针指向的是一整行,故数组指针每加 1 表示跳过一行,而二维字符数组中每一行均代表一个串,因此在二维字符数组中运用数组指针能较便捷地对各个串进行操作。
指针数组
指针数组,即存储指针的数组,数组中的每个元素均是同类型的指针。
指针数组的定义格式为:
类型 *数组名[数组大小];
例如,如下语句定义了一个含有 5 个整型指针变量的一维数组。
- int* a[5];
数组 a 中含有 5 个元素,每个元素均是整型指针类型。
可以分别为数组的各个元素赋值,例如:
- int a0,a1,a2,a3,a4;
- a[0]=&a0;
- a[1]=&a1;
- …
- a[4]=&a4;
也可以使用循环语句把另一个数组中每个元素的地址赋给指针数组的每个元素。例如:
- int i,*a[5],b[]={1,2,3,4,5};
- for(i=0;i<5;i++)
- a[i]=&b[i];
这样指针数组 a 中每个元素 a[i] 中的值,均为 b 数组对应各元素的地址 &b[i],即整型指针。由于 a[i]=&b[i],两边同时加取内容运算符 *,即 *a[i]=*&b[i]=b[i],即通过指针数组中的每个元素 a[i] 可间接访问 b 数组。如下程序可以输出 b 数组中的所有元素。
- for(i=0;i<5;i++)
- printf(“%d\t“,*a[i]);//*a[i]=b[i]
指针数组最主要的用途是处理字符串。在 C 语言中,一个字符串常量代表返回该字符串首字符的地址,即指向该字符串首字符的指针常量,而指针数组的每个元素均是指针变量,故可以把若干字符串常量作为字符指针数组的每个元素。通过操作指针数组的元素间接访问各个元素对应的字符串。例如:
- char* c[4]={“if”,“else”,“for”,“while”};
- int i;
- for(i=0;i<4;i++)//需确定数组元素个数
- puts(c[i]);//输出c[i]所指字符串
上述方法需要知道数组元素个数即该数组中字符串的个数。更通常的做法是,在字符指针数组的最后一个元素(字符串)的后面存一个 NULL 值。NULL 不是 C 语言的关键字,在 C 语言中 NULL 为宏定义:
- #defineNULL((void*)0)
NULL 在多个头文件中均有定义,如 stdlib.h、stdio.h、string.h、stddef.h等。只要包含上述某个头文件,均可以使用 NULL。
上述语句可以修改为:
- char*c[]={“if”,“else”,“for”,“while”, NULL};
- int i;
- for(i=0;c[i]!=NULL;i++)//NULL 代替使用数组大小
- puts(c[i]);
指针与字符串
常量字符串与指针
1) 字符串与字符指针常量
字符串常量返回的是一个字符指针常量,该字符指针常量中保存的是该字符串首字符的地址,即指向字符串中第一个字符的指针。
例如,字符串常量 “abcd” 表示一个指针,该指针指向字符 ‘a’,表达式 “abcd”+1,是在指针 “abcd” 值的基础上加 1,故也是一个指针,指向字符串中第二个字符的指针常量。同理,”abcd”+3 表示指向第 4 个字符 ‘d’ 的指针常量。
由于 “abcd”+1 表示指向字符 ‘b’ 的指针常量,即保存 ‘b’ 的地址,故如下两条语句均是输出从该指针地址开始直到遇到字符串结束符 ‘\0’ 为止的字符串 “bcd”。
- puts(“abcd”+1);
等价于
- printf(“%s\n“,“abcd”+1);
既然字符串返回指针,那么通过间接访问符 *,可以访问该指针所指向的字符,例如: *(“abcd”+1) 表示字符 ‘b’; *(“abcd”+3) 表示字符 ‘d’; *(“abcd”+4) 表示空字符 ‘\0’; *(“abcd”+5) 已越界,表示的字符不确定。
所以,以下两条语句均输出字符 ‘c’。
- putchar(*(“abcd”+2));//输出字符
- printf(“%c”,*(“abcd”+2));//输出字符’c’
以下语句输出空字符(字符串结束符)。
- putchar(*(“abcd”+4));//输出字符串结束符空字符
由于 “abcd”+5 表示的指针已超出字符串存储空间,该指针指向的内容 *(“abcd”+5) 不确定。
- putchar(*(“abcd”+5));//禁止使用。其值不确定
当字符数组名用于表达式时也是作为字符指针常量的,例如:
- char c[]=“xyz”;
数组名 c 为指针常量,即字符的地址,故 c+1 为字符 ‘y’ 的地址,故如下语句输出 yz。
- puts(c+1);//输出yz并换行
字符串和字符数组名均表示指针常量,其本身的值不能修改。如下语句均是错误的。
- c++; //错误。字符数组名c为常量
- “xyz”++;//错误。字符串表示指针常量,其值不能修改
- *(“xyz”+1)=‘d’;//运行时错误。试图把y,变为W
2) 字符串与字符指针变量
在 C 语言中,经常定义一个字符指针变量指向一个字符串,例如:
- char*pc=“abcd”;
定义了一个字符指针变量 pc,并初始化为字符串 ”abcd”,即初始指向字符串的首字符,pc=pc+1; 表示向后移动一个字符单元,pc 保存字符 ‘b’ 的地址,即指向字符 1。通过每次使 pc 增 1,可以遍历字符串中的每个字符。
例如,如下代码段通过指针变量依次遍历输出所指串中每个字符。
程序代码为:
- #include<stdio.h>
- intmain(void)
- {
- //初始指向首字符
- //间接访问所指字符 //pc依次指向后面的字符
- char*pc=“hello,world!”;
- while(*pc!=‘\0‘)
- {
- putchar(*pc);
- pc++;
- }
- return0;
- }
通过字符指针变量可访问所指向的字符串常量,但仅限于“读取”操作,也可以修改字符指针变量的指向,即让其重新指向其他字符串;但不能进行“修改”操作,即不能通过该指针变量,企图改变所指向字符串的内容。有些编译器在编译时可能不报错,但运行时会发生错误。例如:
- char*pc;//正确,未初始化,随机指向
该语句定义了一个字符指针变量,并未显式初始化,属于“野”指针,不能对该指针所指内容进行存取操作。由于 pc 为变量,故可以修改指针的指向,即可以让指针变量 pc 重新指向其他字符串。故如下操作是正确的。
- pc=“abcd”;//正确,让 pc 指向串 “abcd”
- pc=“hello”;//正确,修改pc指向,让其指向串”hello”
此时,字符指针变量 pc 已指向字符串常量 “hello”,不能通过指针修改该字符串常量。 如下操作是错误的。
- *(pc+4)=‘p’;//运行时错误。试图把’o’字符改变为’p’
更不允许企图通过 pc 指针,覆盖其所指字符串常量。如下企图使用 Strcpy 把 “xyz” 串复制并覆盖 pc 所指串 “hello”。
- strcpy(pc,“xyz”);//运行时错误。企图把另一个串复制到pc空间
变量字符串
字符数组可以理解为若干个字符变量的集合,如果一个字符串存放在字符数组中,那么字符串中的每个字符都相当于变量,故该字符串中的每个字符均可以改变,故可把存放在字符数组中的字符串称为变量字符串。
1) 字符数组空间分配 例如:
- char str[10]=“like”;
定义了一个字符数组并显式指定其大小是 10(数组空间应足够大,一般大于等于字符串长度 +1),即占 10 个字符空间,前 5 个空间分别存放有效字符 ‘l’,’i’,’k’,’e’ 及结束符 ‘\0’,多余的空间均用 ‘\0’ 填充。
定义时也可以不显式指定其大小,让编译器根据初始化字符串长度加 1 来自动分配空间大小。例如:
- char s[]=“like”;
编译器为该数组分配 5 个字符空间大小,前 4 个为有效字符第 5 个为结束符 ‘\0’。
2) 访问字符数组元素
使用数组下标的形式可以逐个改变数组中的每个元素,如下所示。
- s[1]=*o‘; //正确。
- s[2] =’v‘;; //正确。’k‘->’v‘
- puts (s); //输出love并换行
可以把字符数组和字符指针联合使用,如下所示。
- char str[]=‘I Like C Language!”;
- char *ps=str;//初始指向字符串首字符”I”
- *(ps+3)=’o‘;//’i‘->’o‘
- *(ps+4)=’v‘;//’k‘->’v‘
- ps=str+2;//ps指向’L‘字符
- puts (ps);//输出 Love C Language!并换行
3) 字符数组访问越界
不管采用数组名加下标形式还是使用字符指针变量访问字符串,一定不能越界。否则可能会产生意想不到的结果,甚至程序崩溃。如下操作均是错误的。
- char c[]=“Nan Jing”,*pc=c+4;//c 大小:9,pc 指向’J’
- c[10]=‘!’;//错误。没有c[10]元素,越界存储,编译器不检查数组是否越界
- *(pc+6)=‘!’;//错误。越界存,pc+6 等价于 c[10]
- putchar(c[9]);//错误,越界取,值不确定
4) 字符串结束符
一般把字符串存放于字符数组中时,一定要存储字符串结束符 ‘\0’,因为 C 库函数中,对字符串处理的函数,几乎都是把 ‘\0’ 作为字符串结束标志的。如果字符数组中没有存储结束符,却使用了字符串处理函数,因为这些函数会寻找结束符 ‘\0’,可能会产生意想不到的结果,甚至程序崩溃。例如:
- char s1[5]=“hello”;//s1不含’\0′
- char s2[]={‘w’,‘o’,‘r’,‘l’,‘d’};//s2大小:5,不含’\0′
- char s3[5];//未初始化,5个空间全为不确定值
- s3[0]=‘g’;
- s3[1]=‘o’;
s3 数组的前两个空间被赋值为 ‘g’ 和 ‘o’,未被显式赋值的 s3[2]、s3[3]、s3[4] 依然为不确定值。即 s3 数组中依然不含有字符串结束符 ‘\0’。s3 数组各元素如下所示(’?’表示不确定值)。
| s3[0] | s3[1] | s3[2] | s3[3] | s3[4] |
|---|---|---|---|---|
| g | o | ? | ? | ? |
故以下操作语句严格来说均是错误的,是被禁止的操作。
- puts(s2);//s2中不含’\0’,输出不确定值,甚至程序崩溃.
- strcpy(s1, s3);//运行时错误。s3中找不到结束符’\0′
注意 s3 数组与如下 s4 数组的区别。
- char s4[5]={‘g’,‘o’};
s4 数组中有 5 个元素,初始化列表中显式提供了两个字符 ‘g’ 和 ‘o’,其他元素使用字符的默认值:空字符,即结束符 ‘\0’。s4 数组各元素如下所示。
| s4[0] | s4[1] | s4[2] | s4[3] | s4[4] |
|---|---|---|---|---|
| g | o | \0 | \0 | \0 |
故对 s4 数组的如下操作语句均是正确的。
- puts(s4);//输出go并换行
- strcpy(s1,s4);//把 s4 中的串 go 和一个’\o’复制到 s1 中。
执行上述语句后,s1 数组中各元素如下所示。
| s1[0] | s1[1] | s1[2] | s1[3] | s1[4] |
|---|---|---|---|---|
| g | o | \0 | 1 | o |
此时,s1 数组中也含有字符串结束符。可以调用字符串处理函数(第一次遇到 ‘\0’ 表示一个串结束),如下所示。
- int len=strlen(s1);// 正确,len 为 2
- puts(s1);//正确,输出go并换行
5) 通过字符指针修改变量字符串
通过字符指针变量可以访问所指字符数组中保存的串,不仅可以读取该数组中保存的字符串,还可以修改该串的内容。原因从数组的本质上理解:数组是一系列相同类型变量的集合,故其中保存的字符串,可以理解为是由若干个字符变量组成的。每个字符变量当然可以改变。
例如:
- #include<stdio.h>
- #include<string.h>
- intmain(void)
- {
- char str[30]=“Learn and live.”
- *p=str;
- *(p+6)=‘A’;
- *(p+10)=‘L’;
- puts(str);
- return0;
- }
该程序中,字符指针 p 指向数组 str 中的字符串,由于该字符串是由一系列字符变量组成的,故通过指针变量 p 可以改变该字符串中的字符。故该程序输出:Learn And Live.。
指针与函数
指针作函教形参——传址调用
在函数章节中,讲述了函数调用的两种形式:传值调用和传址调用,其中,传址调用介绍的是数组类型作函数形参,数组名作实参的形式。
现在介绍传址调用的另外一种形式,即指针变量作函数形参,地址(或其他指针变量)作实参的形式。函数调用时,在函数体内可以通过实参地址间接地对该实参地址对应的空间进行操作,从而实现可以在函数体内改变外部变量值的功能。
传值调用与传址调用的区别如下:
- 传值调用:实参为要处理的数据,函数调用时,把要处理数据(实参)的一个副本复制到对应形参变量中,函数中对形参的所有操作均是对原实参数据副本的操作,无法影响原实参数据。且当要处理的数据量较大时,复制和传输实参的副本可能浪费较多的空间和时间。
- 传址调用:顾名思义,实参为要处理数据的地址,形参为能够接受地址值的“地址箱”即指针变量。函数调用时,仅是把该地址传递给对应的形参变量,在函数体内,可通过该地址(形参变量的值)间接地访问要处理的数据,由于并没有复制要处理数据的副本,故此种方式可以大大节省程序执行的时间和空间。
指针作函教返回类型——指针函教
有时函数调用结束后,需要函数返回给调用者某个地址即指针类型,以便于后续操作,这种函数返回类型为指针类型的函数,通常称为指针函数。
指针函数的定义格式为:
类型*函数名(形参列表)
{
… /*函数体*/
}
指针函数,在字符串处理函数中尤为常见。
例如,编程实现把一个源字符串 src 连接到目标字符串 dest 之后的函数,两串之间用空格隔开,并返回目标串 dest 的地址。
实现代码为:
- #include<stdio.h>
- char*str_cat(char* dest,char* src);
- intmain(void)
- {
- char s1[20]=“Chinese”;//目标串
- char s2[10]=“Dream”;
- char*p=str_cat(s1, s2);//返回地址赋给 p
- puts(p);
- return0;
- }
- //str_cat的参数也可为字符数组形式
- char*str_cat(char* dest,char* src)
- {
- char*p1=dest,*p2=src;
- while(*p1!=‘\0‘)//寻找dest串的结尾,循环结束时,p1指向’\0T字符
- p1++;
- *p1++=‘ ‘;//加空格,等价于*p1=”;p1++;
- while(*p2!=‘\0‘)
- *p1++=*p2++;
- return dest;
- }
运行结果:
Chinese Dream
指向函教的指针——函教指针
在 C 语言中,整型变量在内存中占一块内存空间,该空间的起始地址称为整型指针,可把整型指针保存到整型指针变量中。函数像其他变量一样,在内存中也占用一块连续的空 间,把该空间的起始地址称为函数指针。而函数名就是该空间的首地址,故函数名是常量指针。可把函数指针保存到函数指针变量中。
1) 函数指针的定义
函数指针变量的定义格式为:
返回类型(*指针变量名)(函数参数表);
说明:上述定义中,指针变量名定义括号不能省略,否则,则为返回指针类型的函数原型声明,即指针函数的声明。
例如:
- int*pf(int,int);//该语句声明了一个函数原型,该函数名为pf,该函数含两个int型参数,且该函数返回类型为整型指针类型,即int*。
- int(*pf)(int,int);//该语句定义了一个函数指针变量pf,该指针变量pf可以指向任意含有两个整型参数,且返回值为整型的函数。
如下定义了一个func函数。
- intfunc(int a,int b)
- {
- //…
- }
该函数含有两个整型参数,且返回类型为整型。与 pf 要求指向的函数类型一致,可让 pf 指向该函数,可以采用如下两种方式。
- pf=&func;//正确
- pf=func;//正确。也可省略&
在给函数指针变量赋值时,函数名前面的取地址操作符 & 可以省略。因为在编译时,C 语言编译器会隐含完成把函数名转换成对应指针形式的操作,故加 & 只是为了显式说明编译器隐含执行该转换操作。
有如下三个函数的原型声明:
- voidf1(int);
- intf2(int,float);
- charf3(int,int);
可能有些编译器对类型检查不严格,但严格意义上来说,如下对函数指针的赋值语句均认为是错误的。
- pf=f1;//错误。参数个数不一致、返回类型不一致
- pf=f2;//错误。参数2的类型不一致
- pf=f3;//错误。返回类型不一致
2) 通过函数指针调用函数
例如,如下 f() 函数原型及函数指针变量 pf:
- intf(int a);
- int(*pf)(int)=&f;//正确。pf 初始指向 f()函数
当函数指针变量 pf 被初始化指向函数f()后,调用函数 f() 有如下三种形式。
- int result;
- result=f(2);//正确。编译器会把函数名转换成对应指针
- result=pf(2);//正确。直接使用函数指针
- result=(*pf)(2);//正确。先把函数指针转换成对应函数名
函数调用时,编译器把函数名转换为对应指针形式,故前两种调用方式含义一样,而第三种调用方式,*pf 转换成对应的函数名 f(),编译时,编译器还会把函数名转换成对应指针形式,从这个角度来理解,第三种调用方式走了些弯路。
函数指针通常主要用于作为函数参数的情形。
假如实现一个简易计算器,函数名为 cal(),假设该计算器有加减乘除等基本操作,每个操作均对应一个函数实现,即有 add()、sub ()、mult()、div() 等,这 4 个函数具有相同的参数及返回值类型。即:
- intadd(int a,int b);//加操作
- intsub(int a,int b);//减操作
- intmult(int a,int b);//乘操作
- intdiv(int a,int b);//除操作
定义函数指针变量 int (*pf) (int,int);,该函数指针变量 pf 可分别指向这 4 个函数。
如果用户调用该计算器函数 cal(),希望在不同的时刻调用其不同的功能(加减乘除),较通用的方法,是把该函数指针变量作为计算器函数 cal() 的参数。即:
- //计算器函数
- voidcal(int(*pf)(int,int),int op1,int op2)
- {
- pf(op1,op2);//或者(*pf) (op1,op2);
- }
假如当用户希望调用 cal() 函数实现加操作时,只需把加操作函数名 add() 及加数和被加数作为实参传给 cal () 函数即可;此时 pf 指针指向 add() 函数,在 cal () 函数内通过该函数指针变量 pf 调用其所执行的函数 add ()。可采用如下两种调用方式。
- pf(op1,op2);
或者
- (*pf)(op1,op2);
例如,使用函数指针,编程实现一个简单计算器程序。实现代码为:
- #include<stdio.h>
- voidcal(void(*pf)(int,int),int opl,int op2);
- voidadd(int a,int b);//加操作
- voidsub(int a,int b);//减操作
- voidmult(int a,int b);//乘操作
- intmain(void)
- {
- int sel,x1,x2;
- printf(“Select the operator:”);
- scanf(“%d”,&sel);
- printf(“Input two numbers:”);
- scanf(“%d%d”,&x1,&x2);
- switch(sel)
- {
- case1:
- cal(add,x1,x2);
- break;
- case2:
- cal(sub,x1,x2);
- break;
- case3:
- cal(mult,x1,x2);
- break;
- default:
- printf(“Input error!\n“);
- }
- return0;
- }
- voidcal(void(*pf)(int,int),int opl,int op2)
- {
- pf(opl,op2);//或者(*pf)(opl,op2);
- }
- voidadd(int a,int b)
- {
- int result=(a + b);
- printf(“%d + %d = %d\n“,a,b,result);
- }
- voidsub(int a,int b)
- {
- int result=(a – b);
- printf(“%d – %d = %d\n“, a,b, result);
- }
- voidmult(int a,int b)
- {
- int result=(a * b);
- printf(“%d * %d = %d\n“,a,b,result);
- }
运行结果为:
Select the operator:1
Input two numbers:2 5
2 + 5 = 7
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...






